
A common sentiment you’ll hear from data scientists is that the majority of their day-to-day work is spent collecting and cleaning data. This is a skill many beginner data scientists tend to neglect. It’s much easier to grab an existing clean data-set and start building models instead of creating one from scratch. At SharpestMinds, we strongly encourage some form of data collection during mentorships because it helps develop some important skills and also leads to more creative and unique projects.
One of the more common data collection techniques is web-scraping. The internet is a gold-mine of text and image data, and a great place to bootstrap a novel data-set from. There are many quality open source tools to make web-scraping relatively simple. I prefer Scrapy. It tends to be faster because it lets you run many requests in parallel and it has a lot of features for building robust data pipelines. However, I’ve noticed that beginner programmers have a tough time getting started with Scrapy. In this post, I will present a working example from a personal project of mine and walk through it in detail.
Scraping metal blogs
Below is the full code I used to scrape all the album reviews from the metal blog site angrymetalguy.com. Following this, I walk through it in pieces.
import os
import re
import scrapy
class AngryMetalGuySpider(scrapy.Spider):
name = 'angrymetalguy'
save_dir = 'reviews';
def start_requests(self):
if not os.path.exists(self.save_dir):
os.mkdir(self.save_dir)
url = 'http://www.angrymetalguy.com/category/reviews/'
yield scrapy.Request(url, self.parse)
def parse(self, response):
for url in response.css('h4.entry-title a::attr(href)').getall():
yield scrapy.Request(url, self.parse_review)
next_page = response.css('li.previous-entries a::attr(href)').get()
if next_page is not None:
yield scrapy.Request(next_page, self.parse)
def parse_review(self, response):
title = response.css('h1.entry-title::text').get()
content = response.xpath('string(//div[contains(@class, "entry_content")])').get()
content_cleaned = content.replace('\n', ' ').replace('\xa0', '').replace('\ufeff', '')
content_trimmed = re.sub('Rating:\s?\d\.\d\/5.0.+', '', content_cleaned).strip()
with open('{}/{}.txt'.format(self.save_dir, title), 'w') as f:
f.write(content_trimmed)
yield
First, I import the necessary libraries, os for filesystem commands, re to help with parsing strings and, of course, scrapy to do all the heavy lifting. Then I define a Spider class, giving it an appropriate name.
import os
import re
import scrapy
class AngryMetalGuySpider(scrapy.Spider):
name = 'angrymetalguy'
save_dir = 'reviews';
The name property identifies the spider and Scrapy requires it. save_dir is a custom property I added to specify the directory to save the scraped reviews in. You can run your spider from the command line (assuming is is saved in a file titled angrymetalguy.py ) using:
$ scrapy runspider angrymetalguy.py
The spider will first call the start_requests method:
def start_requests(self):
if not os.path.exists(self.save_dir):
os.mkdir(self.save_dir)
url = 'http://www.angrymetalguy.com/category/reviews/'
yield scrapy.Request(url, self.parse)
This function can be completely replaced by assigning a list of urls to a start_urls property. However, I wanted to run some extra logic before scraping, ensuring that save_dir exists. This function should yield scrapy.Requests to the initial pages you wish to scrape. These functions accept a url to send a request to and a callback function to handle the response. In this case, we only have one start url, and we use our spider’s parse method as the callback function (parse is the default callback if you only provided start_urls).
def parse(self, response):
for url in response.css('h4.entry-title a::attr(href)').getall():
yield scrapy.Request(url, self.parse_review)
Here, response is an object containing the response from the request which, in this case, is an html document (it could also be json or css, or js). This is where one could use a library like BeautifulSoup to parse the html and select the data we need, but scrapy already ships with some useful methods for parsing html. Here, we use response.css()to select all the blog post urls from the page and create separate requests to all of them, using the parse_review method to process the response which I will outline later.
How did I decide on the selector (the string passed to response.css())? This is where some inspection on the page’s source code is necessary. Right click on the part of the website you want to scrape and click Inspect Element. This will open up the inspector in your browser’s developer’s console highlighting that particular element.
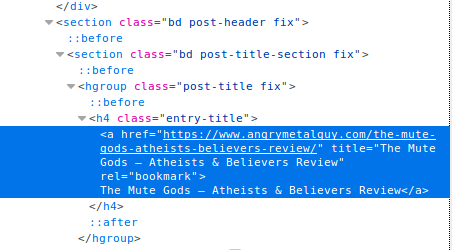
We want to look for something that uniquely identifies the item we want to scrape. In this case, the <a> elements that link to each blog post do not have any distinct attributes, but the parent <h4> element does. Hence the selector: 'h4.entry-title a::attr(href)' (find the h4 element with the entry-title class and select the href attribute of the child a elements). This will match all the urls for reviews on the page, which we can then iterate over using .getall().
Once we parse all the blog posts on the first page, we want to continue on and get urls from older posts. Luckily angrymetalguy.com has paginated their posts with an explicit link the previous page. We can use the same method to select that link (which happens to have a unique class), and start the scraping process over again for the next page. Repeating until we reach the last page and the link in no longer present.
next_page = response.css('li.previous-entries a::attr(href)').get()
if next_page is not None:
yield scrapy.Request(next_page, self.parse)
Now let’s take a look at parse_review which is responsible for scraping the content of each blog post.
def parse_review(self, response):
title = response.css('h1.entry-title::text').get()
content = response.xpath('string(//div[contains(@class, "entry_content")])').get()
We can use a simple css selector to extract the title. To get the content of the review, however, I am using response.xpath() which offers a different syntax for selecting html elements. The xpath selector above is saying “find the div element with the class entry_content and convert all the text within it to a single string”. This was simpler than iterating over all the <p> containing the paragraphs of the review.
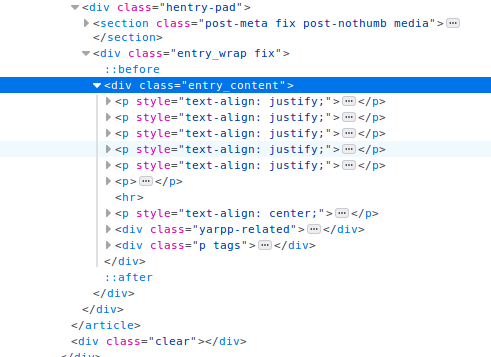
Finally, having our title and blog content, we do some initial cleaning of the data and save the review as a text file. It’s often a good idea to do some initial cleaning during collection to avoid headaches later on in your project.
content_cleaned = content.replace('\n', ' ').replace('\xa0', '').replace('\ufeff', '')
content_trimmed = re.sub('Rating:\s?\d\.\d\/5.0.+', '', content_cleaned).strip()
with open('{}/{}.txt'.format(self.save_dir, title), 'w') as f:
f.write(content_trimmed)
yield
By inspecting the data returned from a few album reviews, I noticed some recurring pesky characters which I simply replaced with empty strings. I also noticed that my selector was returning some additional text with each review which I did not want to save: the album rating followed by some additional tags and links. I was able to filter this out for each blog post with a simple regex replacing the rating and all the content after it with an empty string. This was effective because the pattern was present on every album review. However, if I chose to scrape all the blog posts, which might not have a unique string like Rating: X.X/5.0 to indicate the end, I would have to come up with a more robust solution.
This spider, as is, got me around 5k album reviews from angrymetalguy.com and can be easily adapted for other paginated blogging sites. Websites which serve dynamic content (e.g. infinite scrolling) make this scraping technique harder, though not necessarily impossible. Scrapy’s docs have some tips on how to address that type of problem.

Leave a comment