AI and machine learning algorithms are becoming increasingly relevant in the technology we use and it’s important for everyone to understand the implications. There is a key difference in how machine learning algorithms are programmed compared to traditional algorithms. Instead of being logic-based, they are data-based. We’re going from software that is explicitly programmed (if this condition is true: do a thing; otherwise, do another thing) to software that “learns” to generalize from example data.
Let’s see this in action using a famous machine learning algorithm called Word2Vec. Word2Vec was developed in 2013 by engineers at Google and is widely used, often in combination with other machine learning algorithms. It takes a corpus of words and converts them to vectors. The output of the algorithm is a collection of word-vectors (often called word embeddings) where semantically similar words are given similar word vectors. It’s a really cool algorithm that learns the relative meaning of words and it lets you do interesting mathematical operations on words like: king+woman-man=queen.
Let’s take a look at the output of the Word2Vec algorithm that was trained on a dataset of news articles containing about 100 billion words (thanks Google). If you were to plot the resulting word-vectors, you’d see semantically similar words grouped together. In this case, we have 300 dimensional vectors which are very hard to visualize, so we can apply another algorithm called t-SNE to reduce the dimensionality while preserving most of the information.

Each point above represents a word and words that are close together have similar semantic meaning. But this is too cluttered to get any value from. Let’s add some labels and zoom in on a random word. How about death?
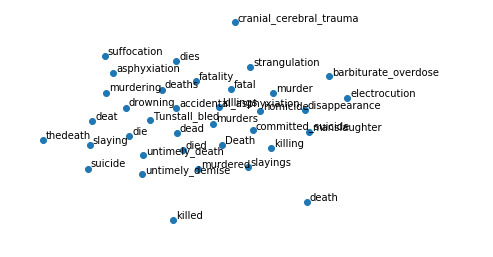
The most similar words to death are what you might expect: murder, killing, fatal. A human would list similar words. The Word2Vec algorithm was never explicitly told that these words were similar, but, by looking at the context in which they were each used (the surrounding words) it learned to give them similar vectors.
Now let’s take the same algorithm and train it on a different set of data. With the help of the fantastic Scrapy library, I’ve created a dataset of blog posts from some of my favourite metal blogs (Angry Metal Guy, Heavy Blog is Heavy, and MetalSucks). Let’s train Word2Vec from scratch on these metal blogs and take a look at death again.

This time we see words like black, power, heavy, folk, sludge, viking, extreme, progressive, thrash, and so on. See the connection? These are all sub-genres of metal! The word death in the metal blog dataset has a completely different semantic meaning!
This is a simple toy example, of course, and easily avoidable with a basic understanding of the data. But it’s not always obvious what biases are lurking in the data. For example, some pre-trained word embeddings have been shown to exhibit gender and racial biases, where certain types of names are considered less “pleasant”. So, as machine learning algorithms take on more and more responsibility, like deciding who to hire or recognizing faces, it’s to be aware of the possibility of algorithmic bias and take extra precaution to prevent it.
Originally published on Medium, 2019/01/30: https://medium.com/@RussellPollari/machine-learning-death-metal-and-algorithmic-bias-a5bc52058d8e

Leave a comment